Tại sao một nhân vật Telugu đang lừa thiết bị của Apple
Apple đã có một vài tháng lỗi. Bây giờ chúng tôi đã có một lỗi nghiêm trọng mới trong chức năng hiển thị văn bản trong iPhone. Lỗi này được kích hoạt bởi một ký tự Telugu duy nhất có thể khiến iPhone xâm nhập vào vòng lặp khởi động không thể phá vỡ chỉ bằng cách nhận thông báo chứa ký tự. Hãy tìm hiểu lý do tại sao một nhân vật có thể gây ra những vấn đề lớn như vậy với iOS.
Lưu ý: Bản sửa lỗi cho lỗi Telugu có sẵn trong phiên bản iOS mới nhất (11.2.6). Nếu ký tự Telugu đã khóa ứng dụng hoặc thiết bị của bạn, hãy khôi phục iPhone của bạn qua iTunes và cập nhật lên phiên bản iOS mới nhất. Nếu iPhone của bạn bị kẹt trong một vòng lặp khởi động, bạn có thể cần phải đặt nó trong trạng thái Cập nhật Firmware Thiết bị (DFU) để iTunes nhận ra nó. Khi hoàn tất, hãy khôi phục thiết bị của bạn từ bản sao lưu gần đây nhất mà bạn hy vọng đã tạo.
Telugu là gì?

Tiếng Telugu là một ngôn ngữ được nói và được viết ở các vùng của Ấn Độ, đặc biệt là các bang của Andhra Pradesh, Telangana và ở thị trấn Yanam. Giống như nhiều ngôn ngữ dựa trên tập lệnh, chẳng hạn như tiếng Ả Rập và các tập lệnh Brahmic khác, Telugu sử dụng một số tính năng đặc biệt của bộ ký tự Unicode để hiển thị các ký tự trên màn hình máy tính.
Trong khi hầu hết các chữ cái Latinh được biểu diễn bằng một điểm mã Unicode 8-bit duy nhất cho khả năng tương thích ASCII (ví dụ, chữ A tồn tại tại điểm mã Unicode U+0041, được biểu diễn bằng nhị phân 01000001 ), các ngôn ngữ được viết bằng tập lệnh hoặc không Chữ cái Latinh thường kết hợp nhiều hơn một điểm mã Unicode để đại diện cho các ký tự của chúng.
Điều này đặc biệt đúng với các ngôn ngữ, như tiếng Telugu, kết hợp các phiên bản của các ngôn ngữ của các chữ cái trong các cụm. Không giống như chữ ghép kiểu cách của tiếng Anh, kết nối giữa mỗi chữ cái Telugu là quan trọng về ngôn ngữ. Để phù hợp với điều này, Unicode bao gồm một hệ thống phức tạp gồm các ký tự đính kèm, mỗi ký tự được đại diện bởi điểm mã riêng của chúng, với nhau.
Xem xét số điểm mã Unicode tuyệt đối, điều này có thể tạo ra sự đa dạng vô hạn. Những điểm này kết hợp với nhau để tạo ra một nhân vật dễ đọc. Bằng cách này Unicode không cần một điểm mã Unicode cho nghĩa đen tất cả các từ Telugu có thể. Thay vào đó, Unicode kết hợp phụ âm tiếng Telugu, nguyên âm và dấu phụ (“virama”) với nhau để tạo các từ được hiển thị như một ký tự đơn. Điều tương tự cũng áp dụng cho các ngôn ngữ khác với các quy tắc chính tả cho chữ ghép, như tiếng Ả Rập.
Nguyên nhân gây ra tai nạn là gì?

Vấn đề có vẻ liên quan đến Zero-Non-Joiner (ZWNJ) tại điểm mã U+200C . ZWNJ yêu cầu hai ký tự liền kề hiển thị mà không có kết cấu điển hình của chúng. Trong tiếng Anh, một ZWNJ giữ các ký tự ff không được in bằng dây kết nối tiêu chuẩn của chúng, thay vào đó tách riêng từng f. Nhưng khi kết hợp với một tập hợp cụ thể của bốn điểm mã Telugu (tất cả đều nên kết hợp với một cụm), vì một lý do nào đó iOS không thể hiển thị kết quả đúng cách.
Một số người đã suy đoán rằng phông chữ San Francisco của Apple không thể hiển thị các nhân vật, trong khi những người khác đã nói rằng quá trình dựng hình cụ thể của Apple sử dụng là để đổ lỗi. Bất kể nguyên nhân chính xác nào, nỗ lực để làm cho nhân vật gây ra một vụ tai nạn đáng kể của bất cứ điều gì là hiển thị nó, từ Tin nhắn và WhatsApp đến Springboard. Các điểm mã Unicode tạo nên ký tự ("gya" có nghĩa là "kiến thức") dưới đây:
U+0C1Cja (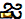 )
)U+0C4Dmột virama, hoặc dấu phụ ( )
)U+0C1Enya (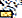 )
)U+200Ckhông chiều rộng không joinersU+0C3Eaa (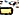 )
)
 )
) )
) )
) )
)Nhưng chúng tôi thậm chí không thể đổ lỗi cho Zero-Non-Joiner (ZWNJ) một mình. Nó cũng được sử dụng trong các biểu tượng cảm xúc gia đình vô hại (????) Mà không có bất kỳ vấn đề gì. Nó có vẻ là một sự kết hợp cụ thể của một số điểm mã cụ thể và ZWNJ. Thêm xúc phạm đến thương tích, có vẻ như ZWNJ hoặc không có hiệu ứng đặc biệt trên kết xuất trên cụm Telugu này hoặc thậm chí nó không nên ở đó ngay từ đầu.
Các vấn đề về tập lệnh Brahmic khác
Tuy nhiên, Telugu không phải là ngôn ngữ duy nhất có vấn đề này. Bengali và Devanagari, sử dụng Unicode theo cách tương tự cho các kịch bản Brahmic của họ, có cùng một vấn đề. Manish Goregaokar viết một bài đăng trên blog hấp dẫn và chi tiết giúp phá vỡ trường hợp sự cố chính xác xuống hơn nữa:
Bất kỳ chuỗi nào
trong Devanagari, Bengali và Telugu, trong đó:1.
consonant2là hậu tố tham gia (pstf/vatu)
2.consonant1âm1 không phải là một lá thư hình thành
3.vowelkhông có hai thành phần glyph
Kết luận: Tại sao điều này không được Apple bắt?
Để hiểu làm thế nào lỗi này đã thông qua, bạn phải đặt mình vào đôi giày của Apple. Chắc chắn, sự kết hợp nhân vật này không phải là một số từ siêu tối nghĩa trong ngôn ngữ Telugu. Nhưng iPhone bao gồm hỗ trợ cho hàng tá ngôn ngữ. Có nghĩa là hàng tỷ kết hợp tiềm năng trong Unicode. Với nhiều điều đó, việc thử nghiệm có ý nghĩa đối với các lỗi Unicode trước khi phát hành sẽ làm cho các bản cập nhật phần mềm thường xuyên về cơ bản là không thể.
Tuy nhiên, lỗi không nên gây ra nhiều thiệt hại này. Điện thoại không nên bị bricked dựa trên nội dung của tin nhắn văn bản. Mặc dù chắc chắn là 20/20, nhưng dường như việc mô tả nhân vật như một hộp câu hỏi ( ) sẽ tốt hơn là phá vỡ Springboard.
![StartMenuXP phục hồi menu Start của bạn thành XP Style [Windows]](http://moc9.com/img/startmenuxp-select-group-option.jpg)